Exploring Kotlin Functional Programming Chapter 1. Thinking Functionally
이 글은 Manning 사 Exploring Kotlin Functional Programming 의 번역입니다.
Thinking Functionally
Why functional programming?
Shared Mutable Data
예기치 않은 가변 값 문제의 이유는 공유되고 있는 변경가능한 자료구조가 1 개 이상의 메서드에 의해 읽히고 업데이트 된다는 것이다. 여러 클래스가 어떤 하나의 리스트의 참조를 갖는다고 가정해보자. 당신은 관리자로써 아래의 질문에 대답할 수 있어야 한다.
- 이 리스트의 소유자는?
- 어떤 한 클래스가 이 리스트를 수정하게 된다면?
- 다른 클래스가 이 변화를 예상하고 있는지?
- 다른 클래스는 이 변화에 대해 어떻게 알 수 있는지?
다시말해, 공유된 변경가능한 자료구조는 프로그램의 다양한 부분에서 변화를 추적하기가 어렵다.
자료구조를 변경하지 않는 시스템 구조를 고려하는것이 좋다. 주변 클래스의 상태나 다른 객체의 상태를 변경하지 않고 리턴을 사용하여 전체결과를 반환하는 방법을 pure 혹은 side-effect-free 라고 한다.
사이드 이펙트란 무엇인가? 간단히 말해, 함수안에 완벽히 둘러싸여 있지 않은 액션을 말한다. 몇 가지 예로,
- 생성자 내부 초기화를 제외한, 임의의 필드에 할당하는 것을 포함하는 자료구조의 수정
- 예외 던지기
- I/O 처리
사이드이펙트 없는 프로그래밍을 위한 다른 관점으로는 불변객체를 사용하는 것이 있다. 불변객체는 이니셜라이즈 된 후에는 자신의 상태를 변경할 수 없는 객체기 때문에 함수의 작용에 영향을 받을 수 없다. 불변객체가 인스턴스화 되면, 예상치못한 상태로 전환될 수 없고, 복사할 필요없이 공유가 가능하며, 수정할 수 없기 때문에 스레드에 안전하다.
Declaraive Programming
먼저, 선언형 프로그래밍의 아이디어를 살펴봅시다. 예를 들어, 리스트에서 가장 고 코스트의 트랜잭션을 계산하려면 일반적으로 일련의 명령을 실행한다. 이런 방식의 프로그래밍은 고전적인 객체지향 프로그래밍에 아주 잘 어울린다.
Transaction mostExpensive = transactions.get(0)
if (mostExpensive == null)
throw new IllegalArgumentException("...");
for (Transaction t: transactions.subList(1, transactions.size())) {
if (t.getValue() > mostExpensive.getValue()) {
mostExpensive = t;
}
}
다른 방법으로는 해야 할 일에 초점을 맞추는 것이다.
Optional<Transaction> mostExpensive =
transactions.stream()
.max(comparing(Transaction::getValue));
이 방식의 큰 이점은 쿼리가 선언처럼 읽힌다는 점이며 이러한 이유로 일련의 명령들을 읽고 이해하는 것에 비해 명 확하다.
이런식의 프로그래밍을 선언형 프로그래밍이라 한다. 원하는 것을 얻는 방법을 선언하고 시스템이 그 목표를 달성하는 방법을 결정하기를 기대한다.
Why Functional Programming?
함수형 프로그래밍은 선언형 프로그래밍과 사이드이펙트 없는 프로그래밍의 예시라고 볼 수 있다. 합성 및 람다전달과 같은 특정 언어의 기능은 선언적 스타일로 코드를 읽고 작성해야 한다. 또한 스트림을 사용해 여러 작업을 체인으로 연결하여 복잡한 쿼리를 표시할 수 있다. 함수형 프로그래밍 스타일을 사용하면 사이드이펙트에 의존하지 않는 프로그래밍이 가능하다.
What’s Functional Programming
함수형 프로그래밍이란 무엇인가? 라는 질문에 대해 간략하게 대답하자면, 함수로 하는 프로그래밍. 이라고 답할 수 있다. 그럼 함수란 무엇인가?
함수형 프로그래밍의 맥락에서 함수는 수학에서의 함수에 해당한다. 함수는 0 개 혹은 여러개의 인자를 받아 하나 이상의 결과를 반환하며 사이드이펙트를 갖지 않는다. 특히 함수는 같은 인자로의 호출에는 몇번을 반복해도 항상 같은 값을 반환한다.
그림. 사이드이펙트를 갖는 함수
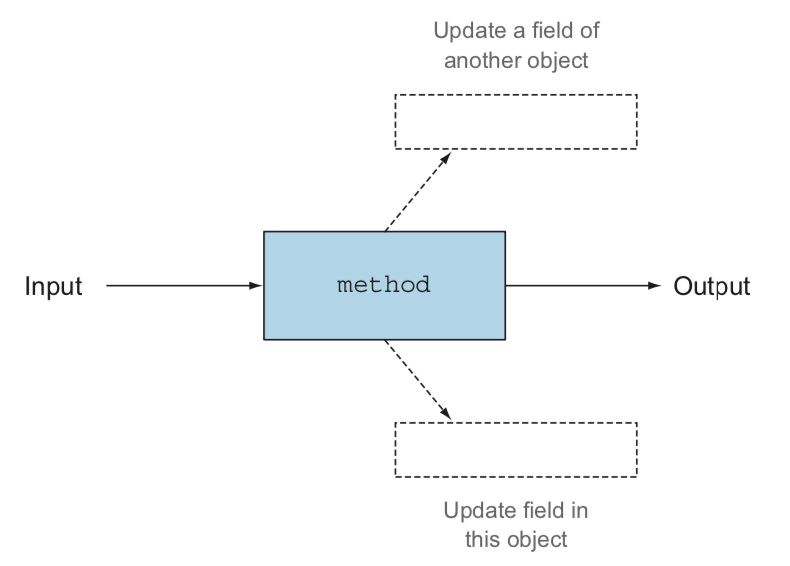
그림. 사이드이펙트가 없는 함수
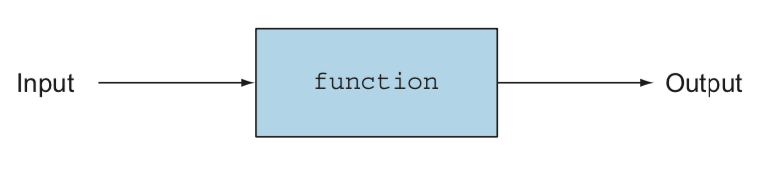
이런 차이가 자바와 같은 프로그래밍에서의 메소드와 함수의 중요한 차이점이다(log 또는 sin 함수에 부작용이 있을리가 없다 와 같은 아이디어).
함수형이라고 말하는 것은, 사이드이펙트를 갖지 않는 수학적인 그것을 의미한다. 이제 프로그래밍의 미묘한 점이 나타난다. 모든게 수학적이라는 것은 모든 함수가 if-then-else 와 같은 수학적인 아이디어로만 작성되야 한다는 것을 의미하는가? 아니면 시스템에 사이드이펙트를 노출시키지 않는 한 내부적으로는 함수가 비함수적인것을 수행할 수 있다는 것을 의미하는가?
다시 말해, 호출자가 관찰 할 수 없는 사이드이펙트를 프로그래머가 수행하게 되면 부작용이 발생하는가? 호출자는 영향을 줄 수 없기 때문에 알거나 신경 쓸 필요가 없다. 이것의 차이를 강조하기 위해, 전자를 순수한 함수형 프로그래밍이라고 하고 후자를 함수형스타일 프로그래밍이라고 부른다.
Functional-style Java
실질적으로, 순수한 함수형 프로그래밍은 자바에서 불가능하다. 자바의 IO 모델은 사이드이펙트를 갖는 메소드들로 구성되어 있다. 그렇지만, 자바의 코어 컴포넌트들을 순수한 함수형 식으로 사용하는 것은 가능하다.
첫번째로, 아무에게도 사이드이펙트가 보이지 않을 수 있기에 함수형적인 의미에서 더 세심한 주의가 필요하다. 실행되고 필드를 증가시킨뒤 다시 감소시키는 것 이외에 사이드이펙트를 갖지 않는 함수나 메서드가 있다고 가정해보자. 단일 스레드로 구성된 프로그램의 관점에서 보자면 이 방법은 눈에 띄는 사이드이펙트가 없고, 함수형이라고 볼 수 있다. 반면에, 다른 스레드가 이 필드를 검사하거나 동시에 메서드를 호출할 수 있는 경우, 이 방법은 함수형이 아니다.
메서드의 내용을 락을 걸어 이슈를 해결할 수 있고, 이렇게 했을때 이 방법이 함수적이라고 주장할 수 있을것이다. 하지만 이렇게 하면, 멀티코어 프로세서에서 코어 두 개을 사용해 메서드를 동시에 호출하거나 하는 일을 할 수 없다.
프로그램은 이 사이드이펙트를 볼 수 없겠지만, 프로그래머에게는 느린 실행속도라는 형태로 확인이 가능하다.
함수형 프로그래밍을 위해 우리가 지켜야할 가이드라인은, 함수나 메서드는 로컬변수에 대해서만 변형을 할 수 있다는 것이다. 또한 참조하는 객체는 불변이어야 한다. 나중에 메서드에서 새로 만든 개체 필드에 대한 업데이트를 허용 할 수 있으므로 다른 곳에서 볼 수 없으며 이후 호출의 결과에 영향을 미치지 않도록 저장되지 않는다.
추가적으로 함수형 프로그래밍에서 함수나 메서드는 어떤 예외도 던져서는 안 된다. 그 뜻은 예외를 던지면 결과가 값을 반환하는 함수를 통해 전달된다는 것을 의미한다(논쟁의 여지는 있다).
그러나 그러한 예외의 사용은 “파라미터를 전달, 결과 반환” 의 구조를 깨뜨리고, 아래 그림처럼 예외를 나타내는 세 번째 화살표로 이어진다.
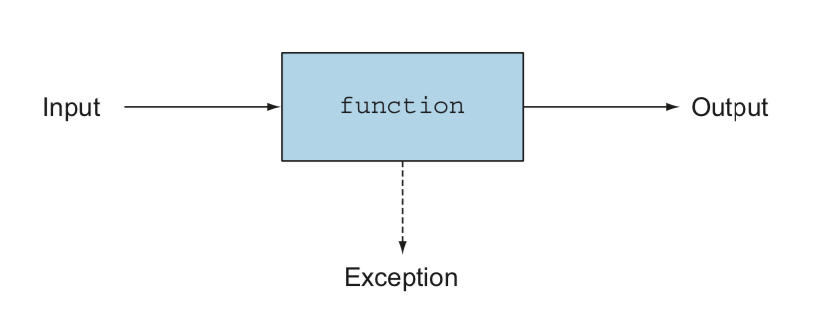
Referential transparency
함수가 동일한 파라미터 값으로 호출될 때 항상 동일한 값을 리턴하면 그 함수는 참조적으로 투명하다고 말한다. 예를 들어, String.replace() 는 참조투명하다고 할 수 있다. “raoul”.replace(“r”, “R”); 는 원본을 변경하는 것이 아니라 항상 같으며 원본을 변경한 것이 아닌 새로운 결과값을 리턴하기 때문이다. 그래서 함수로서의 취급이 가능하다.
달리 말하면 함수는 호출 된 위치와 시간에 관계없이 동일한 입력이 주어진 경우 일관되게 동일한 결과를 생성한다. 이러한 맥락에서 Random.nextInt 는 함수형으로 간주되지 않는지 알 수 있다.
Java에서 Scanner 객체를 사용하여 사용자의 키보드에서 입력을 얻는 것은 nextline 메서드를 호출 할 때마다 각 호출에서 다른 결과를 생성 할 수 있기 때문에 참조 투명성을 위반하게 된다.
참조 투명성은 프로그램 이해에 큰 자산이다. 또한 고비용 또는 긴 작업에 대한 재계산 대신 저장 최적화(메모이제이션 또는 캐싱이라는 이름으로 진행되는 프로세스)를 포함한다.
Java는 참조 투명성과 관련하여 한 가지 약간의 복잡성을 가지고 있다. 리스트를 반환하는 메서드에 대해 두 번 호출을 했다고 가정해 보자. 각각의 호출은 메모리에 별개의 참조를 리턴하지만 같은 내용을 담고 있을수도 있다. 만약 이 리스트가 가변 객체 지향 값으로 보여질 경우, 그 방법은 참조적으로 투명하지 않다.
이러한 리스트를 순수한 값으로 사용할 계획이라면 값을 동일한 것으로 보는 것이 타당하므로 함수는 참조적으로 투명하다. 일반적으로 함수형 스타일 코드에서는 이러한 함수를 참조적으로 투명하게 간주헌다.
Recursion vs. iteration
순수 함수형 프로그래밍 언어는 일반적으로 while 및 for 루프와 같은 반복 구문을 포함하지 않는다. 그런 구조는 종종 숨겨진 가변성을 갖기도 한다. 예를 들어, while 루프의 조건은 업데이트 되어야만 한다. 그렇지 않으면 루프는 무한 횟수로 실행된다.
그러나, 많은 경우에 루프들은 괜찮다. 함수형 스타일에 대해 논의했을때, 아무도 당신이 하는 것을 볼 수 없을 경우에는 뮤터블한 것이 허용되므로 로컬 변수를 변형하는 것은 허용된다.
자바에서 for-each 문을 사용했을 때 그것은 Iterator 를 사용한 코드로 디코드된다.
Iterator<Apple> it = apples.iterator();
while (it.hasNext()) {
Apple apple = it.next();
// ... }
메서드를 호출한 호출자의 시점에서는 변이가 보이지 않기 때문에 이 번역은 문제가 되지 않는다.
그러나 검색 알고리즘과 같이 for-each 루프를 사용하면 루프 바디가 호출자와 공유되는 데이터 구조를 업데이트하기 때문에 다음과 같은 문제가 발생한다.
public void searchForGold(List<String> l, Stats stats) {
for(String s: l) {
if("gold".equals(s)) {
stats.incrementFor("gold");
}
}
}
실제로 루프 본체는 함수형 스타일로 무시할 수 없는 부작용을 가지고 있는데, 그것은 프로그램의 다른 부분과 공유되는 static 객체의 상태를 변화시킨다. 이 때문에, 하스켈과 같은 순수한 함수형 프로그래밍 언어는 그러한 사이드이펙트의 연산을 누락시킨다. 기존의 루프 대신에 불변성을 갖는 재귀를 사용해 프로그램을 작성하자. 재귀를 사용하면 단계별로 업데이트되는 반복 변수를 제거 할 수 있다.
//Iterative factorial
static long factorialIterative(long n) {
long r = 1;
for (int i = 1; i <= n; i++) {
r *= i;
}
return r;
}
//Recursive factorial
static long factorialRecursive(long n) {
return n == 1 ? 1 : n * factorialRecursive(n-1);
}
첫 번째 예제는 표준 루프 기반 형식을 보여준다. 변수 r 과 i는 각 루프에서 업데이트된다. 두 번째 예제는 더 수학적으로 친숙한 형태로 재귀적 정의 (함수 자체를 호출)를 보여준다. Java 에서 재귀는 일반적으로 효율성이 떨어진다. Java 8 에서는 스트림이 팩토리얼을 정의하는 더 단순한 선언적 방법을 제공한다.
//Stream factorial
static long factorialStreams(long n){
return LongStream.rangeClosed(1, n)
.reduce(1, (long a, long b) -> a * b);
}
그렇지만, 효율면에서 한 번 살펴보자. 자바 사용자로서, 당신이 항상 루프 대신에 재귀를 사용해야한다고 말하는 함수형 프로그래밍의 광신도를 조심하라. 일반적으로 재귀 함수 호출을 만드는 것은 반복 할 필요가있는 단일 기계 수준 분기 명령어를 발행하는 것보다 훨씬 더 코스트가 높다.
factorial Recursive 함수가 호출 될 때마다 호출 스택에 새로운 스택 프레임이 만들어져 재귀가 완료 될 때까지 각 함수 호출의 상태 (수행해야하는 곱셈)를 유지한다.
재귀적으로 정의된 팩토리얼은 그 입력에 비례하는 메모리를 사용한다. 이런 이유 때문에 큰 입력으로 함수를 실행하면 StackOverflowError가 발생하기 쉽다.
그러면 재귀는 쓸모 없는것인가? 당연히 아니다. 함수형 언어는 이 문제에 대한 해답을 꼬리 호출 최적화라는 방법으로 제공한다.
꼬리 호출 최적화란 재귀 함수의 맨 마지막에서 재귀호출을 발생시키는 것이다. 이 다른 형태의 재귀 스타일은 빠르게 실행되도록 최적화 될 수 있다. 다음 예제는 tail-recursive 정의를 제공한다.
//Tail-recursive factorial
static long factorialTailRecursive(long n) {
return factorialHelper(1, n);
}
static long factorialHelper(long acc, long n) {
return n == 1 ? acc : factorialHelper(acc * n, n-1);
}
factorialHelper 함수는 재귀 호출이 함수에서 마지막으로 발생하기 때문에 꼬리 재귀적이다. 대조적으로, factorialRecursive의 이전 정의에서, 마지막 것은 n과 반복 호출의 결과를 곱한 것이다.
이러한 형태의 재귀는 재귀의 중간 결과를 각각 별도의 스택 프레임에 저장하는 대신 컴파일러는 단일 스택 프레임을 재사용하기로 결정할 수 있기 때문에 유용하다.
실제로 factorialHelper 의 정의에서 중간 결과(팩토리얼의 부분 결과)는 함수에 대한 인수로 직접 전달된다. 별도의 스택 프레임에서 각 재귀 호출의 중간 결과를 추적 할 필요가 없다. factorialHelper 의 첫 번째 인수로 직접 액세스 할 수 있다.
하지만 나쁜 소식은 Java가 이러한 종류의 최적화를 지원하지 않는다는 것이다. 그러나 꼬리 재귀를 채택하는 것은 컴파일러 최적화로가는 길을 열어줄 수도 있기에, 고전적인 재귀보다 더 나은 방법 일 수 있다.
스칼라, 그루비, 코틀린과 같은 많은 현대 JVM 언어는 루프와 동일한 재귀 사용을 최적화 할 수 있으며 동일한 속도로 실행됩니다.
Java 8 을 작성하는 가이드라인은 종종 루프를 스트림으로 대체하여 변성을 피할 수 있다는 것이다.
또한 재귀를 통해 보다 간결하고 사이드이펙트가 없는 방식으로 알고리즘을 작성할 수있는 경우 루프를 재귀로 대체 할 수 있다.
재귀는 예제를 읽고 쓰고 이해하기 쉽게 만들 수 있으며 프로그래머의 효율성은 실행 시간에서의 작은 차이보다 더 중요한 부분이다.
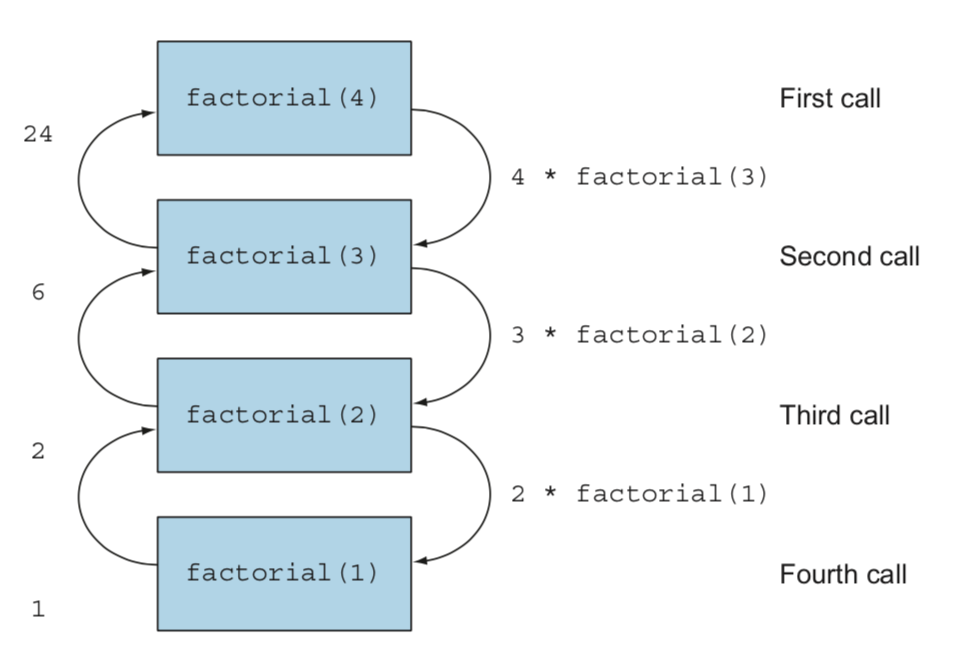 여러 개의 스택 프레임이 필요한 재귀적 팩토리얼의 정의
여러 개의 스택 프레임이 필요한 재귀적 팩토리얼의 정의
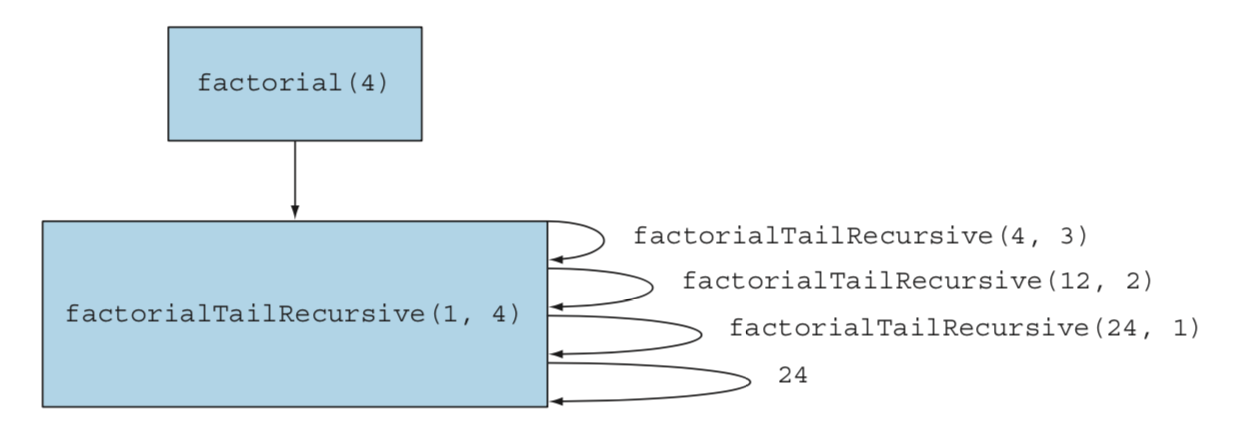 단일 스택 프레임을 재사용할 수 있는 꼬리재귀 팩토리얼의 정의
단일 스택 프레임을 재사용할 수 있는 꼬리재귀 팩토리얼의 정의
Summary
- 공유, 가변 데이터 구조를 줄이면 장기적으로 프로그램을 유지하고 디버그하는 데 도움이 될 수 있다.
- 함수형 프로그래밍은 부작용 없는 방법과 선언적 프로그래밍을 권장한다.
- 함수 스타일 메서드는 입력 인수와 출력 결과에 의해서만 특징지어 진다.
- 동일한 인수 값을 사용하여 호출 할 때 항상 동일한 결과 값을 반환하는 경우 함수는 참조 적으로 투명하다. while 루프와 같은 반복 구문은 재귀로 대체 될 수 있다.
- 꼬리재귀는 잠재적인 컴파일러 최적화를위한 길을 열어주기 때문에 자바의 고전적인 재귀보다 더 나은 방법 일 수 있다.